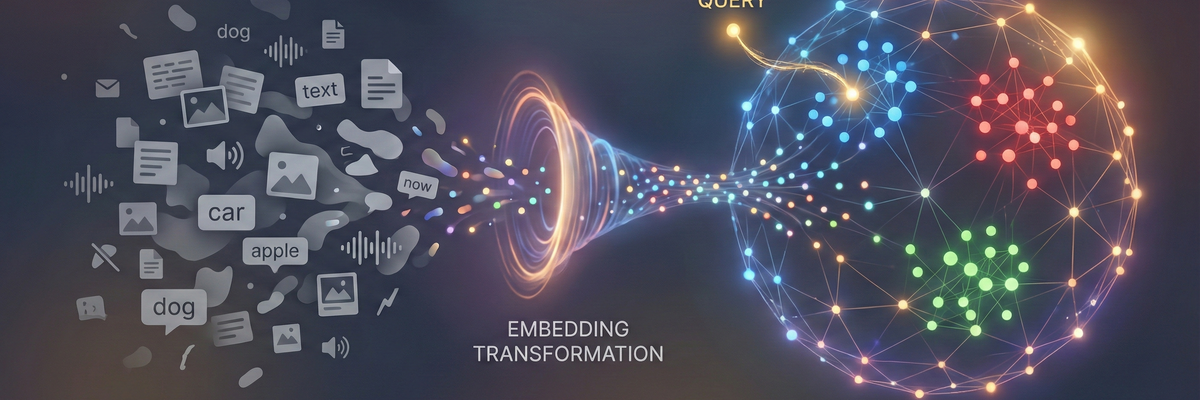
Hier ist eine detaillierte Aufschlüsselung der Funktionsweise, des Retrieval-Prozesses und der Unterschiede zu klassischen Systemen.
1. Das Kernkonzept: Embeddings (Einbettungen)
Um zu verstehen, wie eine Vektordatenbank funktioniert, muss man zuerst verstehen, was sie eigentlich speichert. Sie speichert keine Rohdaten (wie den Text "Apfel"), sondern eine Liste von Fließkommazahlen, die diesen Text repräsentieren.
- Der Vektor: Ein Vektor ist eine Reihe von Zahlen, z. B. [0.12, -0.45, 0.88, ...].
- Der Vektorraum: Stellen Sie sich ein Koordinatensystem vor. Ein 2D-Vektor ist ein Punkt auf einem Blatt Papier. Ein Vektor in einer modernen Datenbank hat jedoch oft 768, 1536 oder mehr Dimensionen.
- Semantische Nähe: In diesem hochdimensionalen Raum liegen Dinge, die eine ähnliche Bedeutung haben, räumlich nah beieinander. "Hund" und "Katze" liegen nah beieinander (beides Haustiere). "Hund" und "Mikrowelle" liegen weit voneinander entfernt.
2. Der Retrieval Prozess (Abruf) im Detail
Der Prozess, wie eine Vektordatenbank eine Antwort findet, unterscheidet sich fundamental von einem SQL-Query. Er läuft in drei Hauptphasen ab:
Phase 1: Vektorisierung (Encoding)
Wenn ein Benutzer eine Suchanfrage stellt (z. B. "Welche Tiere leben im Wasser?"), wird diese Anfrage nicht direkt an die Datenbank gesendet.
- Die Textanfrage wird an dasselbe Embedding-Modell (ein KI-Modell, z. B. von OpenAI oder HuggingFace) gesendet, das auch die Daten in der Datenbank erstellt hat.
- Das Modell wandelt die Frage in einen Vektor um (Query Vector).
Phase 2: Mathematische Ähnlichkeitsberechnung
Die Datenbank muss nun berechnen, welche gespeicherten Vektoren dem Query-Vektor am "nächsten" sind. Dafür nutzt sie mathematische Distanzmaße:
- Kosinus-Ähnlichkeit (Cosine Similarity): Misst den Winkel zwischen zwei Vektoren. Ein Winkel von 0 Grad bedeutet Identität (Wert 1), 180 Grad bedeutet das Gegenteil (Wert -1). Dies ist der Standard für Textmodelle, da die Richtung (Bedeutung) wichtiger ist als die Länge (Menge der Wörter) des Vektors.
- Euklidische Distanz (L2): Misst die direkte Luftlinie zwischen zwei Punkten.
- Dot Product (Skalarprodukt): Misst, wie sehr zwei Vektoren in die gleiche Richtung zeigen und berücksichtigt deren Länge.
Phase 3: Der Suchalgorithmus (ANN vs. k-NN)
Hier liegt die eigentliche Magie der Vektordatenbank.
- k-NN (k-Nearest Neighbors): Dies ist die "brute force" Methode. Die Datenbank vergleicht den Query-Vektor mit jedem einzelnen Vektor in der Datenbank. Das ist extrem präzise, aber bei Millionen von Datensätzen viel zu langsam.
- ANN (Approximate Nearest Neighbors): Vektordatenbanken nutzen stattdessen ANN-Algorithmen. Sie akzeptieren einen minimalen Verlust an Genauigkeit für eine massive Geschwindigkeitssteigerung.
Wie ANN funktioniert (Beispiel HNSW):
Der derzeit beliebteste Algorithmus ist HNSW (Hierarchical Navigable Small World).
- Stellen Sie sich das wie ein System von Autobahnen und lokalen Straßen vor.
- Die Suche beginnt auf der obersten Ebene ("Autobahn"), wo nur wenige Punkte existieren, um schnell in die richtige "Gegend" des Datenraums zu kommen.
- Sobald die Suche in der Nähe des Ziels ist, wechselt sie auf die unteren Ebenen ("lokale Straßen"), um den exakten Nachbarn zu finden.
- So muss die Datenbank nicht Millionen Einträge prüfen, sondern vielleicht nur ein paar Hundert Sprünge machen.
3. Vektordatenbank vs. Klassische Datenbank (RDBMS)
Der Hauptunterschied liegt in der Art der Frage, die Sie stellen können.
| Feature | Klassische Datenbank (SQL/Relational) | Vektordatenbank (z. B. Pinecone, Milvus, Weaviate) |
|---|---|---|
| Datenstruktur | Tabellen (Zeilen & Spalten), feste Schemata. | Vektoren (Arrays von Zahlen) + Metadaten (JSON). |
| Suchlogik | Exakter Abgleich (Keyword Match). WHERE color = 'red' | Semantische Ähnlichkeit (Semantic Match). "Finde Dinge, die wie 'rot' wirken." |
| Abfrage | "Finde den Datensatz mit ID 10." | "Finde die 5 Datensätze, die diesem Bild/Text am ähnlichsten sind." |
| Flexibilität | Scheitert bei Tippfehlern oder Synonymen (sucht man nach "Auto", findet man "PKW" nicht). | Versteht Synonyme und Kontext ("Auto" und "PKW" liegen im Vektorraum nah beieinander). |
| Datentypen | Text, Zahlen, strukturierte Daten. | Unstrukturierte Daten: Bilder, Audio, lange Texte, Video. |
| Sprachen | Es ist nicht möglich, deutsch Inhalte mit Fragen in englischer Sprache zu finden. | Suche nach “mountain”, “montagne” oder “monte” finden deutsche Seiten, in denen es um Berge geht, da die Bedeutung des Wortes in allen Sprachen gleich ist |
Praktische Beispiele
Stellen Sie sich vor, Sie suchen in einer Produktdatenbank nach "etwas, um im Winter warm zu bleiben".
- Klassische DB: Findet nichts, es sei denn, ein Produkt enthält exakt diese Wörter in der Beschreibung.
- Vektordatenbank: Der Vektor für "Winter warm bleiben" liegt nah bei den Vektoren für "Daunenjacke", "Wollmütze" und "Heizlüfter". Sie erhalten diese Produkte als Ergebnis, obwohl die Suchbegriffe in der Produktbeschreibung gar nicht vorkommen.
Alle Inhalte sind in deutscher Sprache gespeichert, ein Besucher spricht aber nur englisch.
- Klassische Suche: Wird keine Ergebnisse liefern
- Vektordatenbank mit KI-Unterstützung wird sowohl die Frage verstehen, die Inhalte finden und in der Sprache der Frage antworten.
Zusammenfassung
Eine Vektordatenbank ist im Grunde eine geometrische Suchmaschine. Sie übersetzt Bedeutung in Koordinaten. Der Retrieval-Prozess ist ein Navigieren durch diesen Koordinatenraum mittels intelligenter Abkürzungen (ANN), um Inhalte zu finden, die kontextuell relevant sind, statt nur exakte Wortübereinstimmungen zu suchen.
Möchten Sie wissen, wie man eine solche Datenbank konkret mit Python aufsetzt (z. B. für einen eigenen Chatbot)?